ドイツ戦車問題(ベイズ推定) [科学、数学]
最近テレビのワイドショーなどでも出てくるベイズという言葉
ベイズというと、感度とか特異度とか偽陽性などの話題で出てくるベイズの定理が有名(?)ですが、ベイズの定理の考え方に基づき、観測されたデータから、知りたい値を推定するベイズ推定という便利な手法があります。
観測されたデータだけから、全体を知るという例では、第二次世界大戦中に連合軍がドイツの戦車の生産台数を推定した「ドイツ戦車問題:The German Tank Problem 」が有名です。
Wikippediaでは、Frequentist analysisの手法としてMinimum-variance unbiased estimator (最小分散不偏推定)とBayesian analysisの手法の説明が書かれています。
https://en.wikipedia.org/wiki/German_tank_problem
Bayesian analysisの手法では、こんな感じで、観測されたドイツの戦車のシリアル番号から、全体の生産台数を推計します。

ベイズ推定をPyStanというpythonのHMCのライブラリで計算してみました。
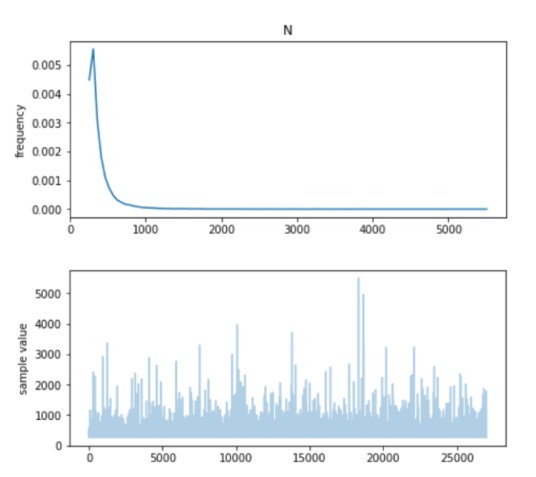
384台という答えになりました。

ベイズというと、感度とか特異度とか偽陽性などの話題で出てくるベイズの定理が有名(?)ですが、ベイズの定理の考え方に基づき、観測されたデータから、知りたい値を推定するベイズ推定という便利な手法があります。
観測されたデータだけから、全体を知るという例では、第二次世界大戦中に連合軍がドイツの戦車の生産台数を推定した「ドイツ戦車問題:The German Tank Problem 」が有名です。
Wikippediaでは、Frequentist analysisの手法としてMinimum-variance unbiased estimator (最小分散不偏推定)とBayesian analysisの手法の説明が書かれています。
https://en.wikipedia.org/wiki/German_tank_problem
Bayesian analysisの手法では、こんな感じで、観測されたドイツの戦車のシリアル番号から、全体の生産台数を推計します。
ベイズ推定をPyStanというpythonのHMCのライブラリで計算してみました。
import numpy as np
import pystan
stan_code = """
data {
int k; // number of serial numbers observed
real D[k]; // serial numbers
}
parameters {
real N;
}
model {
N ~ uniform(max(D), 10000); // P(N)
D ~ uniform(0, N); // P(D|N)
}
"""
#観測されたシリアル番号
samples = np.array([10, 256, 202, 97])
stan_data = {'D': samples, 'k': len(samples)}
fit = pystan.stan(model_code=stan_code, data=stan_data,
warmup=1000, iter=10000, chains=3, thin=1, seed=123)
fig = fit.plot()
Inference for Stan model: anon_model_5136330356b462f8eee190f0cbd5e79c.
3 chains, each with iter=10000; warmup=1000; thin=1;
post-warmup draws per chain=9000, total post-warmup draws=27000.
mean se_mean sd 2.5% 25% 50% 75% 97.5% n_eff Rhat
N 384.08 1.83 202.91 257.81 281.12 322.93 407.51 888.09 12338 1.0
lp__ -19.49 0.01 0.84 -21.89 -19.68 -19.16 -18.95 -18.89 6950 1.0
Samples were drawn using NUTS at Sun Aug 9 16:21:59 2020.
For each parameter, n_eff is a crude measure of effective sample size,
and Rhat is the potential scale reduction factor on split chains (at
convergence, Rhat=1).
print(fit.extract()['N'].mean())384.0790990985663
384台という答えになりました。




コメント 0