秋の気配 [科学、数学]
8月も最後になって、暑い日が続いていますが、もう銀杏がなっていました。


だいぶお疲れのようです。

8月のはじめには、大きくなったヒナがいたけど、もうどこかに飛び立って行ってしまいました。

今週の自由研究
UCI Machine Learning Repository のBank Marketing Data Set ( https://archive.ics.uci.edu/ml/datasets/bank+marketing : ポルトガル銀行の2008年5月〜2010年11月のダイレクトマーケティングの結果)のデータから、マーケッティングの結果定期預金の予約をした顧客の属性とコンタクト回数などマーケッティングの条件をRのarulesパッケージのアプリオリ(apriori)・アルゴリズムを使って調べ、効果的なマーケテイングの条件を探してみました。
アプリオリって、紙おむつとビールみたいな、高頻度のパターンを探すのが普通みたいですけど、今はコンピュータのメモリも沢山あって、CPUも速いので、定期預金の予約のような確率の低いものも、できるかもしれない...
データファイルbank-full.csv2を読み込んで、各変数のサマリを表示します。 bank-full.csv2は、TAB区切り形式なのでread.csv2を使っています。
変数名yの値がyesの数値が、定期預金を予約した顧客の数です。 45,211件のうち5,289件、全体の12%弱が定期預金を予約しています。 どのような、条件のときに予約を行ってくれることが多いのか、アプリオリ(apriori)・アルゴリズムを使ったバスケット解析の手法で調べてみます。
Rのarulesパッケージでは、アプリオリ・アルゴリズムを使ってバスケット解析を行うためにテーブル型のデータを、トランザクション型のデータに変換する必要がありますが、このままトランザクション型に変換しようとすると、数値型データのカラムがエラーになってしまいます。
df <- read.csv2("datasets/bank-full.csv2")
data.tran <- as(df, "transactions")
Error in asMethod(object) : column(s) 1, 6, 10, 12, 13, 14, 15 not logical or a factor. Discretize the columns first.
一度as関数を実行させてエラーを発生させてから、エラー・メッゼージを参考に数値型データのカラムをfactorに変換した後にトランザクション型変換にすれば大丈夫です。
apriori関数を使って、定期預金の予約(y=yes)になる頻度の高い項目の組合せを見つけます。
定期預金を予約したときの条件(ルール)をliftの大きい順に並べ最も効果の大きかった条件を探します。
住宅ローン無し (housing=no), パーソナル・ローン無し (loan=no), 携帯電話でコンタクト (contact=cellular), 以前のマーケティング・キャンペーンで成功した(poutcome=success) 顧客が定期預金を予約した割合は、平均の6.046230倍で、最も高いことがわかります。
住宅ローン無し, パーソナル・ローン無し, 携帯電話でコンタクト, 以前のマーケティング・キャンペーンで成功した顧客へのマーケテイングは、無作為にマーケティングを行う場合の6倍効果があるということにになります。
liftの上位8件全てに住宅ローン無し (housing=no)と以前のマーケティング・キャンペーンで成功した(poutcome=success)が含まれており、この2つの条件を満たす顧客へのマーケティングが効果が高いことがわかります。
aprioriの結果が正しいか確認のため、全体の定期預金の予約したかどうかの集計結果と、住宅ローン無しで以前のマーケティング・キャンペーンで成功した顧客が定期預金を予約したかどうかの結果を比べてみます。
住宅ローン無しで以前のマーケティング・キャンペーンで成功した顧客は、70%以上、定期預金を予約してくれています。 しかし、よく見るとこの条件に合わない顧客の予約も4,560件(5,289-729)あります。
まず「住宅ローン無しで以前のマーケティング・キャンペーンで成功した顧客に対するマーケテイングを重点的に行い、その他の顧客に対してもチャンスを逃さないようにする。」というのが効果的なようです。
RのarulesVizというパッケージを利用すると、分析の結果をグラフィカルに表示することができます。
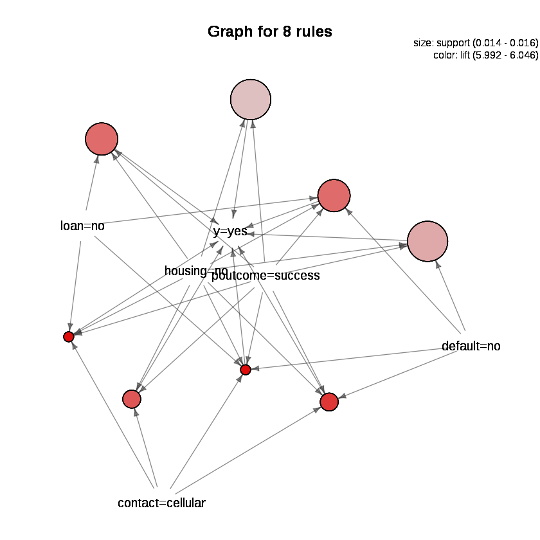
このようなマーケティングのデータの分析は、決定木 (decision tree) を使うのが、普通のようなので、試しにRのrpartとrpart.plotを使って、決定木を描いてみました。
(duration 12番目の変数については、モデルを作るときは、除くようにと書いてあったので、削除します。
duration: last contact duration, in seconds (numeric). Important note: this attribute highly affects the output target (e.g., if duration=0 then y='no'). Yet, the duration is not known before a call is performed. Also, after the end of the call y is obviously known. Thus, this input should only be included for benchmark purposes and should be discarded if the intention is to have a realistic predictive model.)
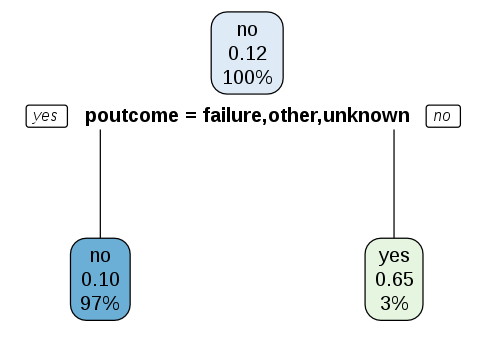
poutcomeだけ?
ちょっとさみしい...
だいぶお疲れのようです。
8月のはじめには、大きくなったヒナがいたけど、もうどこかに飛び立って行ってしまいました。
今週の自由研究
UCI Machine Learning Repository のBank Marketing Data Set ( https://archive.ics.uci.edu/ml/datasets/bank+marketing : ポルトガル銀行の2008年5月〜2010年11月のダイレクトマーケティングの結果)のデータから、マーケッティングの結果定期預金の予約をした顧客の属性とコンタクト回数などマーケッティングの条件をRのarulesパッケージのアプリオリ(apriori)・アルゴリズムを使って調べ、効果的なマーケテイングの条件を探してみました。
アプリオリって、紙おむつとビールみたいな、高頻度のパターンを探すのが普通みたいですけど、今はコンピュータのメモリも沢山あって、CPUも速いので、定期預金の予約のような確率の低いものも、できるかもしれない...
データファイルbank-full.csv2を読み込んで、各変数のサマリを表示します。 bank-full.csv2は、TAB区切り形式なのでread.csv2を使っています。
library(arules)
df <- read.csv2("bank-full.csv2")
summary(df)
age job marital education
Min. :18.00 blue-collar:9732 divorced: 5207 primary : 6851
1st Qu.:33.00 management :9458 married :27214 secondary:23202
Median :39.00 technician :7597 single :12790 tertiary :13301
Mean :40.94 admin. :5171 unknown : 1857
3rd Qu.:48.00 services :4154
Max. :95.00 retired :2264
(Other) :6835
default balance housing loan contact
no :44396 Min. : -8019 no :20081 no :37967 cellular :29285
yes: 815 1st Qu.: 72 yes:25130 yes: 7244 telephone: 2906
Median : 448 unknown :13020
Mean : 1362
3rd Qu.: 1428
Max. :102127
day month duration campaign
Min. : 1.00 may :13766 Min. : 0.0 Min. : 1.000
1st Qu.: 8.00 jul : 6895 1st Qu.: 103.0 1st Qu.: 1.000
Median :16.00 aug : 6247 Median : 180.0 Median : 2.000
Mean :15.81 jun : 5341 Mean : 258.2 Mean : 2.764
3rd Qu.:21.00 nov : 3970 3rd Qu.: 319.0 3rd Qu.: 3.000
Max. :31.00 apr : 2932 Max. :4918.0 Max. :63.000
(Other): 6060
pdays previous poutcome y
Min. : -1.0 Min. : 0.0000 failure: 4901 no :39922
1st Qu.: -1.0 1st Qu.: 0.0000 other : 1840 yes: 5289
Median : -1.0 Median : 0.0000 success: 1511
Mean : 40.2 Mean : 0.5803 unknown:36959
3rd Qu.: -1.0 3rd Qu.: 0.0000
Max. :871.0 Max. :275.0000
変数名yの値がyesの数値が、定期預金を予約した顧客の数です。 45,211件のうち5,289件、全体の12%弱が定期預金を予約しています。 どのような、条件のときに予約を行ってくれることが多いのか、アプリオリ(apriori)・アルゴリズムを使ったバスケット解析の手法で調べてみます。
Rのarulesパッケージでは、アプリオリ・アルゴリズムを使ってバスケット解析を行うためにテーブル型のデータを、トランザクション型のデータに変換する必要がありますが、このままトランザクション型に変換しようとすると、数値型データのカラムがエラーになってしまいます。
df <- read.csv2("datasets/bank-full.csv2")
data.tran <- as(df, "transactions")
Error in asMethod(object) : column(s) 1, 6, 10, 12, 13, 14, 15 not logical or a factor. Discretize the columns first.
一度as関数を実行させてエラーを発生させてから、エラー・メッゼージを参考に数値型データのカラムをfactorに変換した後にトランザクション型変換にすれば大丈夫です。
df[,1] <- factor(df[,1]) df[,6] <- factor(df[,6]) df[,10] <- factor(df[,10]) df[,12] <- factor(df[,12]) df[,13] <- factor(df[,13]) df[,14] <- factor(df[,14]) df[,15] <- factor(df[,15]) data.tran <- as(df, "transactions")
apriori関数を使って、定期預金の予約(y=yes)になる頻度の高い項目の組合せを見つけます。
rules<- apriori(data.tran, parameter = list(supp = 0.01, conf = 0.7)) rules_yes <- subset(rules, subset = rhs %in% 'y=yes')
定期預金を予約したときの条件(ルール)をliftの大きい順に並べ最も効果の大きかった条件を探します。
top.lift <- sort(rules_yes, decreasing = TRUE, by = "lift")
inspect(top.lift[1:min(10,length(top.lift))])
lhs rhs support confidence lift
[1] {housing=no,
loan=no,
contact=cellular,
poutcome=success} => {y=yes} 0.01411161 0.7073171 6.046230
[2] {default=no,
housing=no,
loan=no,
contact=cellular,
poutcome=success} => {y=yes} 0.01411161 0.7073171 6.046230
[3] {default=no,
housing=no,
contact=cellular,
poutcome=success} => {y=yes} 0.01464245 0.7050053 6.026469
[4] {housing=no,
contact=cellular,
poutcome=success} => {y=yes} 0.01464245 0.7042553 6.020058
[5] {housing=no,
loan=no,
poutcome=success} => {y=yes} 0.01559355 0.7035928 6.014395
[6] {default=no,
housing=no,
loan=no,
poutcome=success} => {y=yes} 0.01559355 0.7035928 6.014395
[7] {default=no,
housing=no,
poutcome=success} => {y=yes} 0.01612439 0.7016362 5.997669
[8] {housing=no,
poutcome=success} => {y=yes} 0.01612439 0.7009615 5.991902
住宅ローン無し (housing=no), パーソナル・ローン無し (loan=no), 携帯電話でコンタクト (contact=cellular), 以前のマーケティング・キャンペーンで成功した(poutcome=success) 顧客が定期預金を予約した割合は、平均の6.046230倍で、最も高いことがわかります。
住宅ローン無し, パーソナル・ローン無し, 携帯電話でコンタクト, 以前のマーケティング・キャンペーンで成功した顧客へのマーケテイングは、無作為にマーケティングを行う場合の6倍効果があるということにになります。
liftの上位8件全てに住宅ローン無し (housing=no)と以前のマーケティング・キャンペーンで成功した(poutcome=success)が含まれており、この2つの条件を満たす顧客へのマーケティングが効果が高いことがわかります。
aprioriの結果が正しいか確認のため、全体の定期預金の予約したかどうかの集計結果と、住宅ローン無しで以前のマーケティング・キャンペーンで成功した顧客が定期預金を予約したかどうかの結果を比べてみます。
summary(df[,"y"]) summary(df[df$housing == "no" & df$poutcome == "success","y"]) no 39922 yes 5289 no 311 yes 729
住宅ローン無しで以前のマーケティング・キャンペーンで成功した顧客は、70%以上、定期預金を予約してくれています。 しかし、よく見るとこの条件に合わない顧客の予約も4,560件(5,289-729)あります。
まず「住宅ローン無しで以前のマーケティング・キャンペーンで成功した顧客に対するマーケテイングを重点的に行い、その他の顧客に対してもチャンスを逃さないようにする。」というのが効果的なようです。
RのarulesVizというパッケージを利用すると、分析の結果をグラフィカルに表示することができます。
library(arulesViz)
plot(rules_yes, method="graph", measure="support",
shading="lift")
このようなマーケティングのデータの分析は、決定木 (decision tree) を使うのが、普通のようなので、試しにRのrpartとrpart.plotを使って、決定木を描いてみました。
(duration 12番目の変数については、モデルを作るときは、除くようにと書いてあったので、削除します。
duration: last contact duration, in seconds (numeric). Important note: this attribute highly affects the output target (e.g., if duration=0 then y='no'). Yet, the duration is not known before a call is performed. Also, after the end of the call y is obviously known. Thus, this input should only be included for benchmark purposes and should be discarded if the intention is to have a realistic predictive model.)
library(rpart) library(rpart.plot) model = rpart(y ~ ., data = df[,c(-12)]) model rpart.plot(model)
poutcomeだけ?
ちょっとさみしい...




コメント 0